How to build a React.js and Lambda app with git push continuous deployment
An open-source example repository and technical deep-dive on using AWS SAM, Golang, CodePipeline and CloudFormation to automate continuous delivery.

Architecture at a glance

Stack at a glance
AWS Serverless Application Model (SAM)
React.js frontend
S3 static site hosting for the frontend
Git push deploys via CodePipeline
Entire code pipeline codified in a CloudFormation template
This tutorial and its example repository provide an in-depth look at how to create a complete full-stack application that extracts links for users, allows them to download them to CSV, and saves metrics and job information in a DynamoDB table.
It also demonstrates how to build a complete code pipeline that continuously deploys the frontend application and the Golang lambda stack everytime you git push to the main branch of your Github repository.
Overview
All of the resources that comprise the code pipeline as well as the application itself are codified via CloudFormation templates, making it simple and fast to standup and teardown the application and the CI/CD pipeline as needed.
Along the way, I’ll share some things I learned while developing this application.
Advantages of this stack
This stack places a premium on develop productivity and ease of maintenance for a single developer or small team. It’s also reasonable scalable as is, so it’s a great choice for a startup, proof of concept, minimum viable product or a side project that you’re just trying to get off the ground. If your requirements should shift down the road due to increased demand, it leaves you with avenues for scaling up quickly.
We can develop locally and use git push to deploy
Thanks to the AWS Serverless Application Model (SAM), we can actually run our lambda locally as we develop it, shortening our feedback loop. SAM uses some Docker magic to simulate the AWS runtime pretty well on your development machine.
If you setup your AWS credential profiles locally and pass your profile flag when running the sam local start-api command, you can even pass in credentials allowing your Lambda to access cloud resources such as DynamoDB tables, which can be very handy during development:
# the docs say otherwise, but for Golang I've found you always need to build your latest app before running it locally
sam build
# run your Lambda locally, passing in your credentials to access cloud resources
sam local start-api --profile <your-aws-profile-name>Thanks to the full codepipeline and the included Github webhook, once our changes look good locally, we just git push to build and deploy the latest SAM backend and the React.js app frontend.
One of the classic difficulties with serverless solutions was developing locally and testing out your solution on your own machine. Lots of progress has been made in this area over the past few years, and SAM is especially easy to develop locally. While building this app, I would run the backend on port 3000 and then run React frontend on port 3001 and point it at the local API.
We can use cross-stack references for shared information
In this example, the React.js frontend uses the value of an environment variable:
REACT_APP_API_URLto know which endpoint to send API requests to. This makes it more portable across deployments and easier to run locally and in production. But in the case of our completely automated code pipeline, the endpoint URL for our Lambda is created at runtime, once the associated CloudFormation template has been successfully deployed. So how can the UI know which endpoint to bake in at build-time?
The CloudFormation template includes an example of a cross-stack dependency, which allows us to reference an output that is exported by the SAM CloudFormation template, and then imported by the UI CodeBuild project as an environment variable.
Read more about CloudFormation exports and the CloudFormation ImportValue function here.
Static sites hosted via S3 are robust
By building our React.js app as a Single Page Application (SPA) and delivering it to S3 for static website hosting, we get a frontend that is robust to failure. To further enhance its speed and resiliance to high demand, we could easily put a Cloudfront distribution in front of it.
It’s been said that “static sites don’t break” and while that does not mean that nothing can go wrong, it does mean there are less points of failure once your application is successfully built and pushed to S3.
CloudFormation makes it easier to use CodePipeline
I’ve set up CI/CD pipelines before using the AWS UI, and I found it extraordinarily painful. It’s often the case that it’s easier to work with AWS services via their APIs, SDKs or Infrastructure as Code tools like Terraform or CloudFormation, and CodePipeline is no exception.
I found it much easier to understand and debug the relationships between resources while instrumenting the pipeline in pure CloudFormation YAML. This tutorial and its repository includes the complete CloudFormation template that codifies every resource that is required by the entire pipeline.
That means that with this single command you go from having nothing to a fully-working git push deployment pipeline:
aws cloudformation deploy \
--template-file code-pipeline.yaml \
--stack-name pageripper-code-pipeline \
--profile <your-aws-profile-name> \
--region us-west-2 \
--parameter-overrides GithubOAuthToken=$GITHUB_OAUTH_TOKEN \
--capabilities CAPABILITY_NAMED_IAMLambda simplifies our maintenance story
Since our backend is a Lambda behind an API Gateway and talking to DynamoDB, we don’t need to worry about managing individual instances, defining or tweaking autoscaling groups, or provisioning for our database tier.
Lambda’s default scalability is pretty reasonable, so for simple applications, prototypes, initial proofs of concept or minimum viable products, this stack is a solid choice that gives us plenty of room to grow via increased concurrency limits if traffic picks up.
SAM ships with solid monitoring and tracing
By using SAM, we get Xray out of the box for distributed tracing of our requests through our backend.
Decoupled frontend and backend
With the frontend served via S3 and the backend handled by Lambda, we can independently scale our two tiers depending on their load.
Depending on your company or team size, it’s also probable that two different teams might “own” the frontend and the backend, and this app serves as a good starting point for creating.
How the code pipeline works
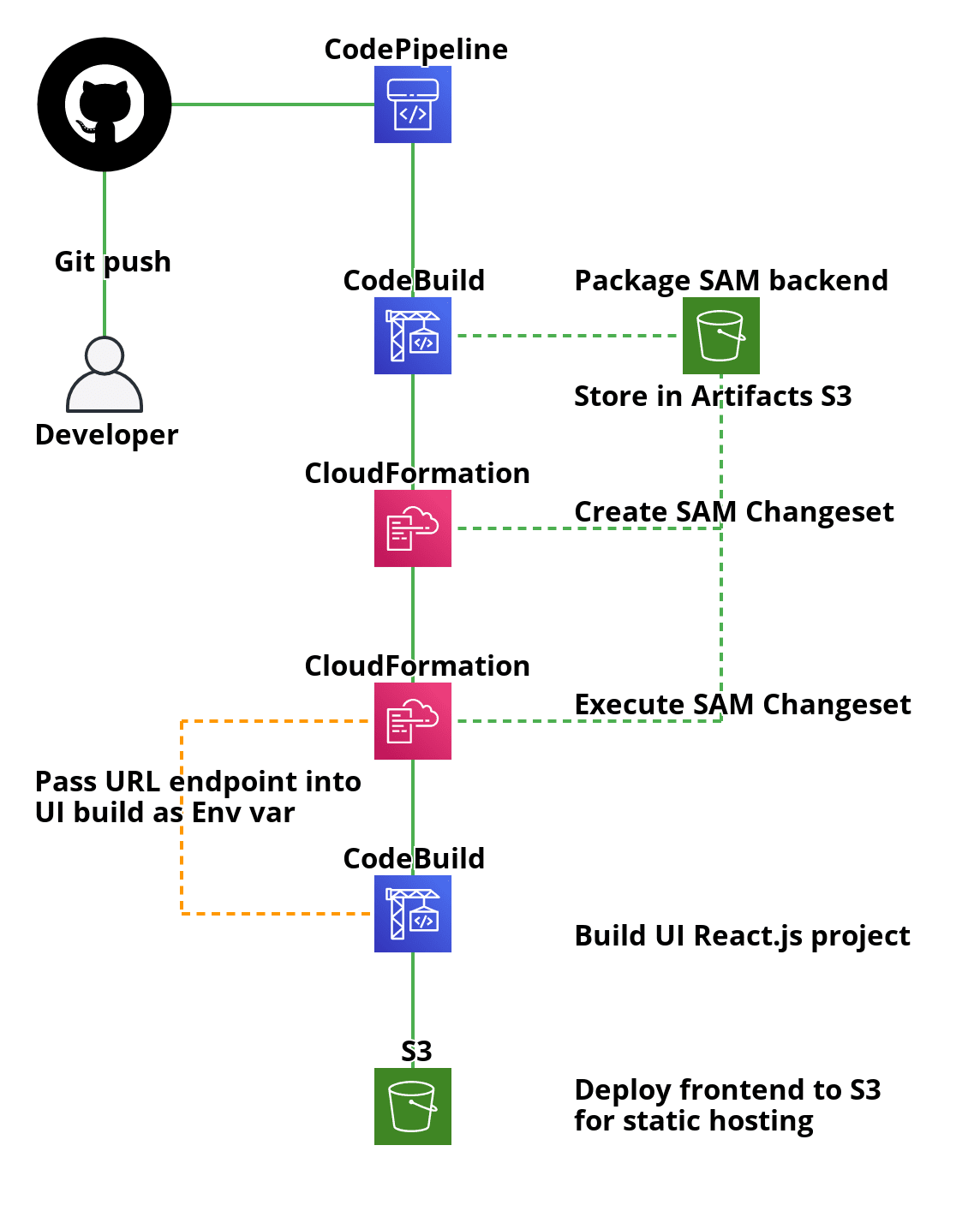
Starting with the source
Github hosts our monorepo that contains all the code for the frontend, backend and the codepipeline itself. In our CloudFormation template for the pipeline, we define this Github repo as a CodePipeline source.
We also define a Github webhook that serves as a trigger for kicking off the pipeline everytime a new commit is pushed.
# This creates a Github webhook that listens for pushes to the repository. Pushes cause the Source step defined in the CodePipeline to run,
# fetching the latest code from the Github repository so that the subsequent CodeBuild steps can be run on it
GithubWebhook:
Type: 'AWS::CodePipeline::Webhook'
Properties:
AuthenticationConfiguration:
SecretToken: "{{resolve:secretsmanager:arn:aws:secretsmanager:us-west-2:675304494746:secret:GithubSecret-QJikjM:SecretString:token}}"
Filters:
- JsonPath: "$.ref"
MatchEquals: refs/heads/{Branch}
Authentication: GITHUB_HMAC
TargetPipeline: !Ref Pipeline
TargetAction: Source
Name: GithubWebhook
TargetPipelineVersion: !GetAtt Pipeline.Version
RegisterWithThirdParty: 'true'Resolving dynamic resources like secrets in CloudFormation templates
In the above example, we need to give CloudFormation the Github personal access token we created so that it can register a secure webhook with Github, to be notified when new commits are pushed.
However, we also need to securely store this Github secret to ensure it’s not accidentally leaked anywhere, stored in source control in plaintext where it could be read, or otherwise exposed because it grants a specific level of access to our Github account.
Therefore we store it in AWS Secrets Manager, and provide the ARN of our secret in the template above via a dynamic reference as demonstrated in the above code snippet. This allows CloudFormation to securely access our secret at runtime, and for us to keep secrets out of our configuration so that we can check it into version control and even open-source it.
Understanding SAM’s deployment model
This was the piece that initially tripped me up the most as a first-time user of SAM. As a result, it also made the code pipeline harder to build because my mental model of a SAM deployment was incorrect. See the diagram above for a visual representation of the full flow. Here’s the key points to understand as well as some tips to avoid common pitfalls:
When running sam locally, and using Go as your Lambda runtime, you still need to call sam build each time before calling sam local start-api, otherwise your latest changes to your Golang source won’t be reflected in your local API. The docs might say otherwise in certain places, but this was my experience.
When you run sam package, you’re creating a CloudFormation template that describes your serverless architecture, including your function, your API gateway configuration, and a link to either the image you created that contains your Lambda function, or the code zip file that was placed into the artifact S3 bucket. This is why the —s3-bucket flag exists.
The above template uses a Macro to describe a Serverless application, which is why it may appear surprisingly condensed and terse. There’s some automation baked into SAM and CloudFormation that abstracts away some of the extra work for you such as creating IAM roles, making the declaration of prefabricated roled for your Lambda function simpler, etc. The code pipeline YAML included in this project is by comparsion verbose, because it’s spelling out all of the resources and their configuration necessary.
Because sam package only gets your Lambda code uploaded and its associated CloudFormation template built, the most important thing to understand is that you must next take these artifacts and use CloudFormation to to create or update the changeset they represent, and then execute that changeset. This is what the custom code pipeline described in this project does. This was the hardest part of this project to figure out, but I cobbled it together via some scattered AWS documentation and various example Github repositories that others had thankfully open-sourced.
Pageripper application flow at a glance
Let’s first take a look at the overall application flow, before we examine each component in more detail.

How the Frontend works
The frontend is a React.js app that accepts a URL from the user. The frontend does some basic validation on the user’s input, ensuring they specify the scheme (http or https) and that it’s a valid looking URL.
The frontend then passes this URL to the API endpoint specified by its environment variable:
REACT_APP_API_URLto initiate the link extraction process. If the backend returns an error, the frontend displays that error to the user, allowing them to correct their input or enter a new target site.
If the frontend recieves a successful response from the backend, the JSON returned will contain two arrays, one of extracted links and one of the ranking of hostnames the site links to. The frontend will immediately render these into easy to read tables and display a Download button that allows the user to download this info into a CSV file.
How the backend works
The backend is a Golang program that leverages goroutines to do work as efficiently as possible. There are several main tasks for the backend to perform once it receives a target URL from the frontend:
Fetch the HTML at the target URL
In a goroutine, parse the the HTML, look through all the nodes of <a> type (links) and collect their href values, sending them into a channel
While parsing, send their hostnames into a separate channel
In a goroutine, make a call to DynamoDB to update the total system count of pages processed (“ripped”) by the app over time
In a goroutine, fetch this latest count so that it can be returned to the frontend with the response containing the links and hostnames extracted
Note that it’s not considering mission critical that the count of total pages ripped be incremented exactly once before being returned each time - it’s more important that the app feel responsive and snappy.
The main point of doing this work in goroutines is to ensure that the work of performing asynchronous tasks like the network calls to the target URL, parsing through the HTML, and calling DynamoDB are done in paraellel, not in sequence.
The main handler function of the Golang Lambda has logic to wait for the final “all processing is complete” signal on a special channel and only then will it return all the processed results to the frontend.
Most pages are processed in anywhere from 0.8 to 2.4 seconds depending on fluctuating network latency at any given time, and whether or not the given Lambda is pre-warmed at the time of the user’s request. If the above steps were performed serially, we’d see responses taking 6 to 9 seconds, at which point many users would grow impatient and bounce from the app.
Next steps and possible improvements
If you found this useful and want to experiment with it or extend the application yourself for practice or your own purposes, feel free to do so. Here’s a couple of ideas for ways you could further expand and improve upon the current codebase:
Codify the Route53 resources necessary to map a custom domain name to your app. This could be done in the SAM CloudFormation template - and the public hosted zone and AWS Alias record would need to point to the static S3 hosting bucket that the React.js app gets deployed to.
Instrument SNS notifications within the code pipeline. You could email yourself notifications of failed or successful builds, test failures, etc.
Write a shell script that glues together all the commands necessary to deploy the application and the codepipeline together, which is smart enough to fail with a legible error if any step in the process should fail
Instrument authorization on your SAM API Gateway so that only your frontend UI is able to make requests to your backend API.
Write info about each job processed to DynamoDB. Information could include the target URL, the links found and the hostnames extracted, and a timestamp for when the job was processed. Extend the Lambda application logic to first check if an entry from a site exists (and if its recent enough to use by examining the timestamp) and fetch it from DynamoDB if it is available instead of scraping it from the web.
Thanks for reading!
I hope you enjoyed this tutorial and companion example repository, and that they were helpful to you in some way. If you have feedback please let me know via LinkedIn or by opening a Github issue against the repository. Be sure to subscribe if you’d like to be notified about more content like this in the future!